Published
- 6 min read
Kafka

Understanding Kafka: A Comprehensive Guide
If you prefer video over text you can refer to this video
Hands on building producer, consumers using GoLang | Topics, Partitions , Broker
Have you ever clicked on a product while shopping online and immediately received suggestions for related items? For instance, clicking on an iPhone might lead to recommendations for AirPods. This rapid response is largely due to technologies like Apache Kafka. In this blog, we will explore Kafka: its architecture, how it operates, and how to set it up using GoLang.
Why Do We Need Kafka?
In our data-driven world, every action generates data. Whether you’re liking a post on social media or making a purchase online, data is created and has a story to tell. For instance, if you buy an iPhone, an effective recommendation system should suggest complementary products like AirPods immediately, rather than days later.
This is where Kafka shines. Kafka is designed to handle event-driven communication, ensuring that data is processed quickly and efficiently. It allows businesses to act on data in real-time, enhancing user experience and driving sales. With around 80% of Fortune 100 companies using Kafka, understanding its mechanics is becoming an essential skill in the tech industry.
Publisher-Subscriber Architecture
Kafka operates on a publisher-subscriber model, which is foundational to modern microservices architecture. In traditional systems, services often depend on one another, leading to tight coupling and potential failures. For instance, if a payment system goes down, the entire order process can be halted.
Using a message queue like Kafka allows services to communicate asynchronously. Instead of waiting for responses, services can publish messages to a queue, and other services can subscribe to listen for those messages. This decouples the services, making the entire system more resilient and scalable.
Kafka Architecture Explained
Kafka’s architecture consists of several key components:
- Topics: Categories under which messages are published.
- Producers: Applications that publish messages to topics.
- Consumers: Applications that subscribe to topics to read messages.
- Brokers: Kafka servers that store and manage the messages.
- Partitions: Each topic can be split into multiple partitions to ensure scalability and fault tolerance.
Messages in Kafka are essentially just arrays of bytes, meaning Kafka doesn’t need to understand the content of the messages. This design allows Kafka to handle large volumes of messages efficiently.
How Kafka Handles Messages
When a producer sends messages, they are grouped together and sent in batches. This batching, along with message compression, allows Kafka to move data quickly and efficiently. Each message is assigned an offset, which helps consumers track what messages they have processed, ensuring that they can resume from where they left off if needed.
Understanding Topics and Partitions
Topics in Kafka function as message queues. Each topic can have multiple partitions, which enables parallel processing of messages. When a producer writes a message, it can specify which partition to send the message to, allowing for load balancing and increased throughput.
For example, if a topic has three partitions, messages can be distributed across them, ensuring that no single partition becomes a bottleneck. This design makes Kafka highly scalable and efficient.
Kafka Brokers and Clusters
Brokers are the backbone of Kafka. They store the messages and manage the distribution of messages across partitions. In a cluster setup, multiple brokers work together, ensuring that if one broker fails, others can take over without data loss.
To prevent data loss, Kafka replicates partitions across different brokers. This means that each partition has multiple copies stored in different brokers. If one broker goes down, the system can still function using the replicas.
Why is Kafka So Fast?
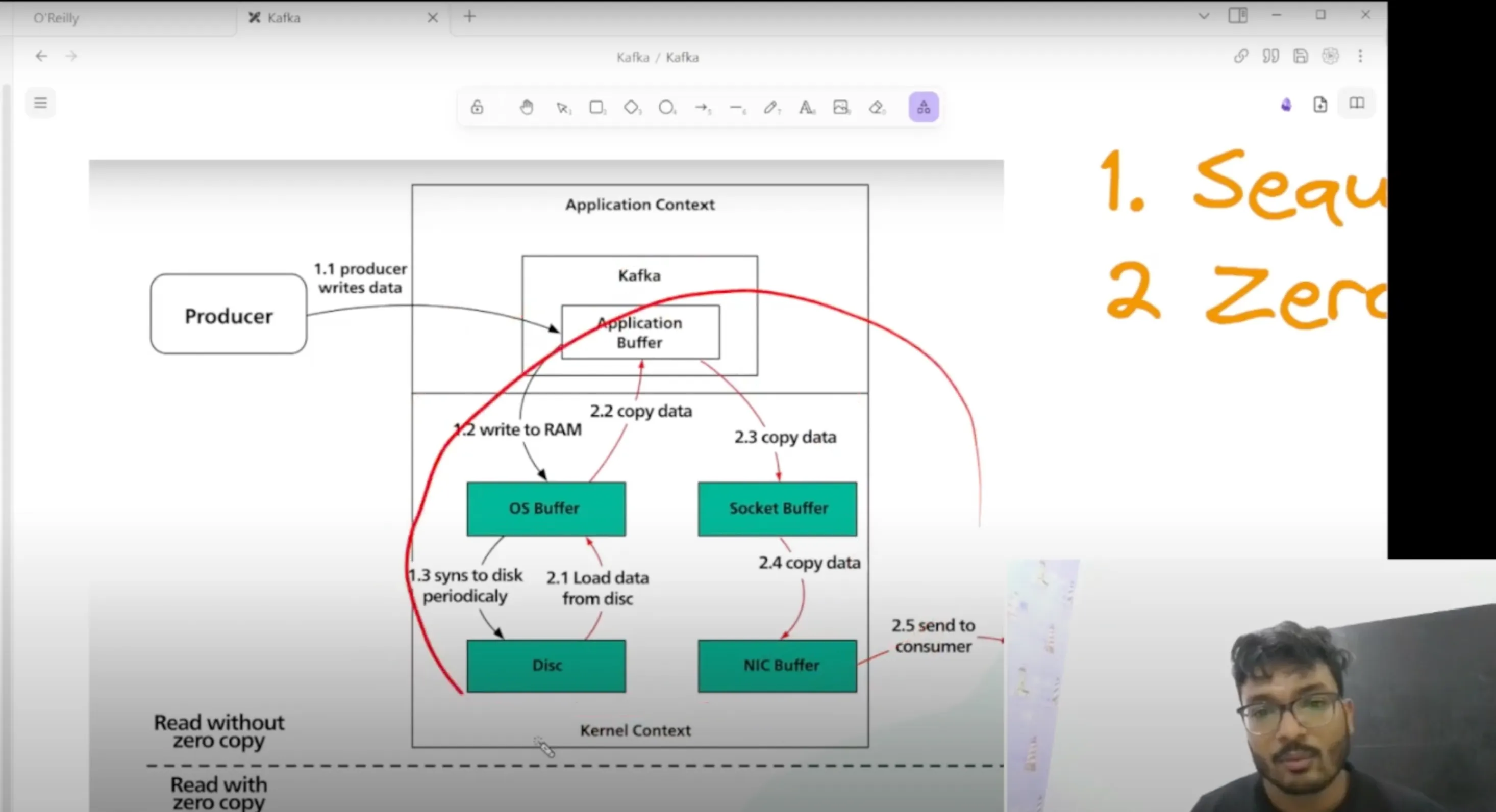
Two main principles contribute to Kafka’s speed:
- Sequential I/O: Kafka writes messages in a sequential manner, which optimizes disk access and minimizes latency.
- Zero Copy: This principle reduces the number of times data is copied during processing, allowing for faster data transfer from disk to network.
Setting Up Kafka with Docker
Now that we understand the theory behind Kafka, let’s dive into a practical setup using Docker. Docker allows us to run Kafka in isolated containers, making it easier to manage dependencies and configurations.
To start, you’ll need Docker installed on your system. Once you have Docker set up, you can create a Docker Compose file to define your Kafka and Zookeeper services. Here’s a simple example:
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper:3.4.6
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:latest
ports:
- "9092:9092"
expose:
- "9093"
environment:
KAFKA\_ADVERTISED\_LISTENERS: INSIDE://kafka:9093,OUTSIDE://localhost:9092
KAFKA\_LISTENER\_SECURITY\_PROTOCOL\_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA\_LISTENERS: INSIDE://0.0.0.0:9093,OUTSIDE://0.0.0.0:9092
KAFKA\_ZOOKEEPER\_CONNECT: zookeeper:2181With this configuration, you can bring up your Kafka environment by running:
docker-compose up -dBuilding a GoLang Microservice
Once Kafka is up and running, we can create a simple GoLang microservice that acts as both a producer and a consumer. We’ll use the segmentio/kafka-go library to interact with Kafka.
First, create a directory for your project and initialize a Go module:
mkdir kafka-example
cd kafka-example
go mod init kafka-exampleNext, install the Kafka library:
go get github.com/segmentio/kafka-go
Now, let’s create a simple producer that publishes messages to a Kafka topic:
package main
import (
"context"
"fmt"
"log"
"time"
"github.com/segmentio/kafka-go"
)
func main() {
writer := kafka.NewWriter(kafka.WriterConfig{
Brokers: \[\]string{"localhost:9092"},
Topic: "test-topic",
})
for i := 0; i < 10; i++ {
err := writer.WriteMessages(context.Background(),
kafka.Message{
Key: \[\]byte(fmt.Sprintf("Key-%d", i)),
Value: \[\]byte(fmt.Sprintf("Hello World %d", i)),
},
)
if err != nil {
log.Fatal("failed to write messages:", err)
}
time.Sleep(time.Second)
}
}This code creates a Kafka writer that sends ten messages to a topic called “test-topic”. Each message has a key and a value.
Creating the Consumer
Next, we’ll build a consumer that reads messages from the same topic:
package main
import (
"context"
"fmt"
"log"
"github.com/segmentio/kafka-go"
)
func main() {
reader := kafka.NewReader(kafka.ReaderConfig{
Brokers: \[\]string{"localhost:9092"},
Topic: "test-topic",
GroupID: "consumer-group",
})
for {
m, err := reader.ReadMessage(context.Background())
if err != nil {
log.Fatal(err)
}
fmt.Printf("received: %s\\n", string(m.Value))
}
}This code sets up a Kafka reader that continuously reads messages from the “test-topic”. Each time it reads a message, it prints the value to the console.
Conclusion
Kafka is a powerful tool for handling real-time data streams. Its architecture allows for efficient data handling, making it an essential component in modern applications. By understanding its fundamentals and how to implement it with tools like Docker and GoLang, you can leverage Kafka to build robust, scalable systems.
If you want to learn more about Kafka, consider exploring the official documentation or joining online communities. Happy coding!